-
Physics-Informed Neural Compression of High-Dimensional Plasma Data
We introduce Physics-Inspired Neural Compression (PINC) for plasma turbulence that achieves up to 70,000x size reduction of 5D gyrokinetic snapshots while maintaining key physical characteristics.
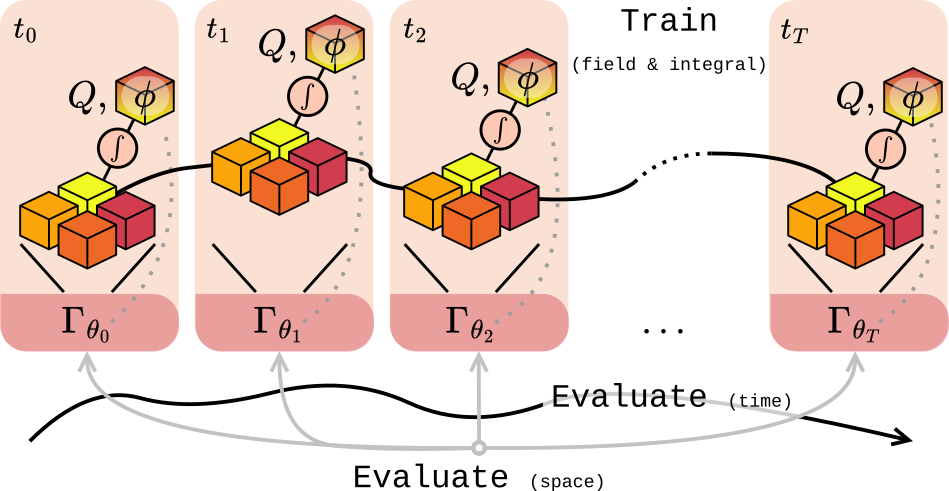
-
GyroSwin: 5D Surrogates for Gyrokinetic Plasma Turbulence Simulations
We develop a 5D neural surrogate model, called GyroSwin, for nonlinear gyrokinetic simulations of plasma turbulence. GyroSwin is scalable, efficient and physically verifiable, paving the way towards deployment of neural surrogates for plasma turbulence simulations.
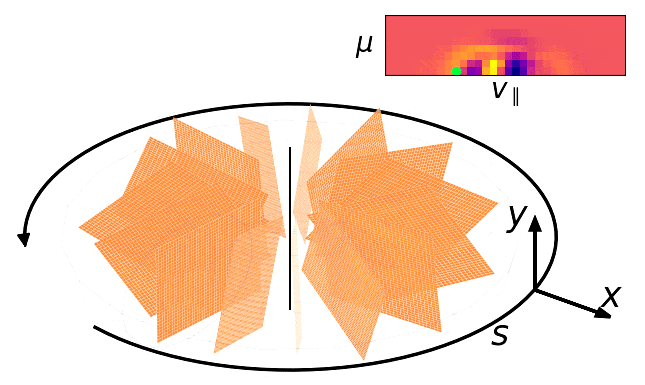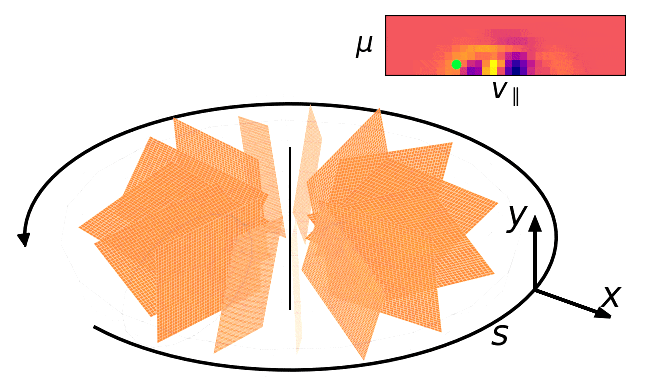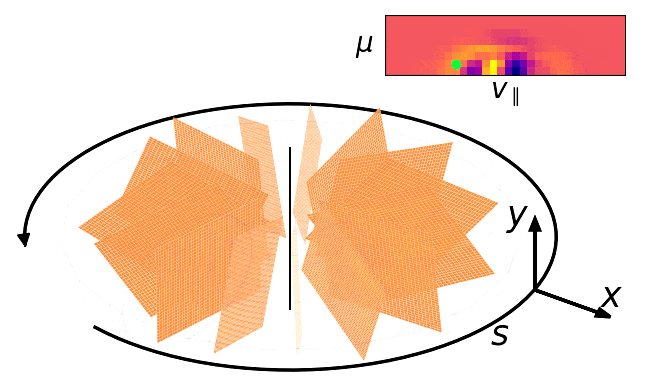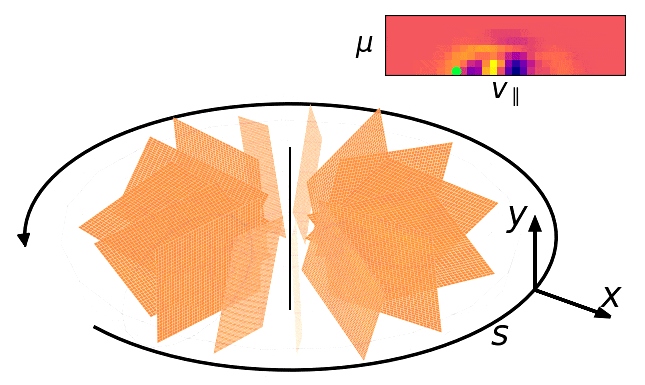
-
A Dataset Perspective on Offline Reinforcement Learning
We investigate how the characteristics of the dataset influence Offline RL algorithms. Towards that end, we introduce measures that capture how explorative or exploitative a policy is. We found, that popular algorithms in Offline RL are strongly influenced by the characteristics of the dataset and that the average performance across different datasets might not be enough for a fair comparison.

-
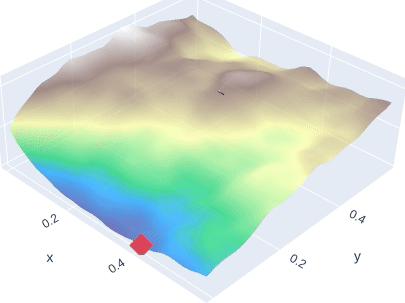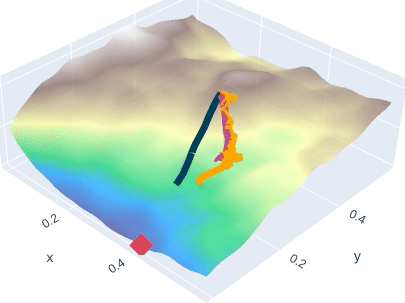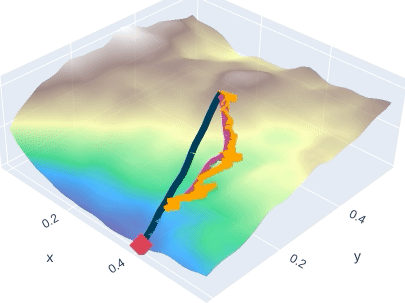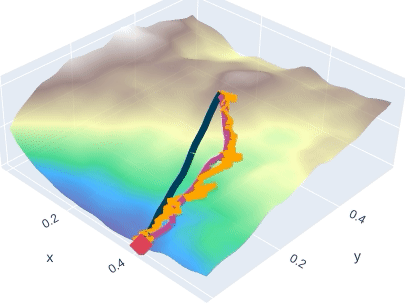
Few-Shot Learning by Dimensionality Reduction in Gradient Space
SubGD is a few-shot learning method that restricts fine-tuning to a low-dimensional parameter subspace. This reduces model complexity and increases sample efficiency. SubGD identifies the subspace through the most important update directions during fine-tuning on training tasks.
-
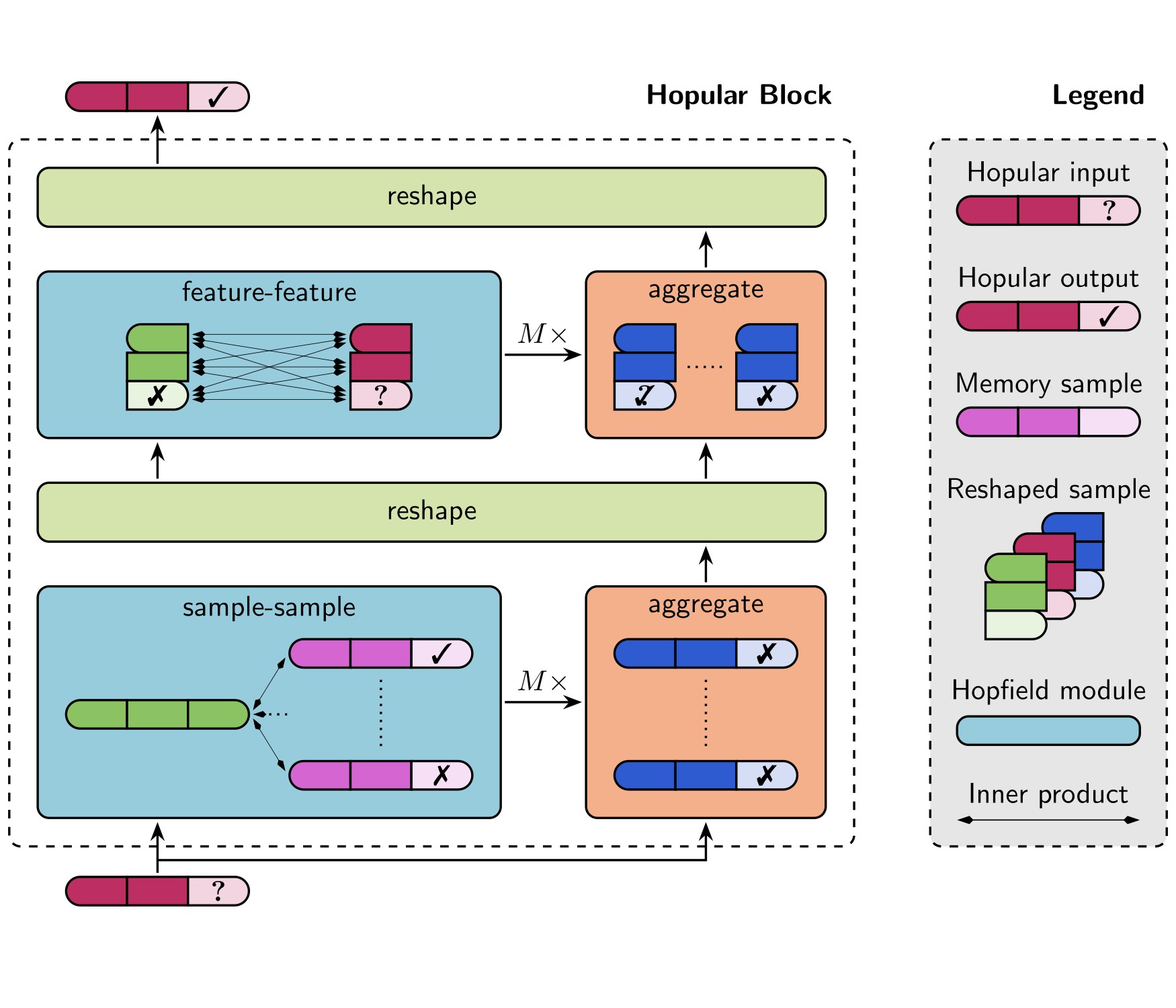
Hopular: Modern Hopfield Networks for Tabular Data
Hopular is a novel Deep Learning architecture where every layer is equipped with an external memory. This enables Hopular to mimic standard iterative learning algorithms that refine the current prediction by re-accessing the training set.
-
History Compression via Language Models in Reinforcement Learning
HELM (History comprEssion via Language Models) is a novel framework for Reinforcement Learning (RL) in partially observable environments. Language is inherently well suited for abstraction and passing on experiences from one human to another. Therefore, we leverage a frozen pretrained language Transformer (PLT) to create abstract history representations for RL.
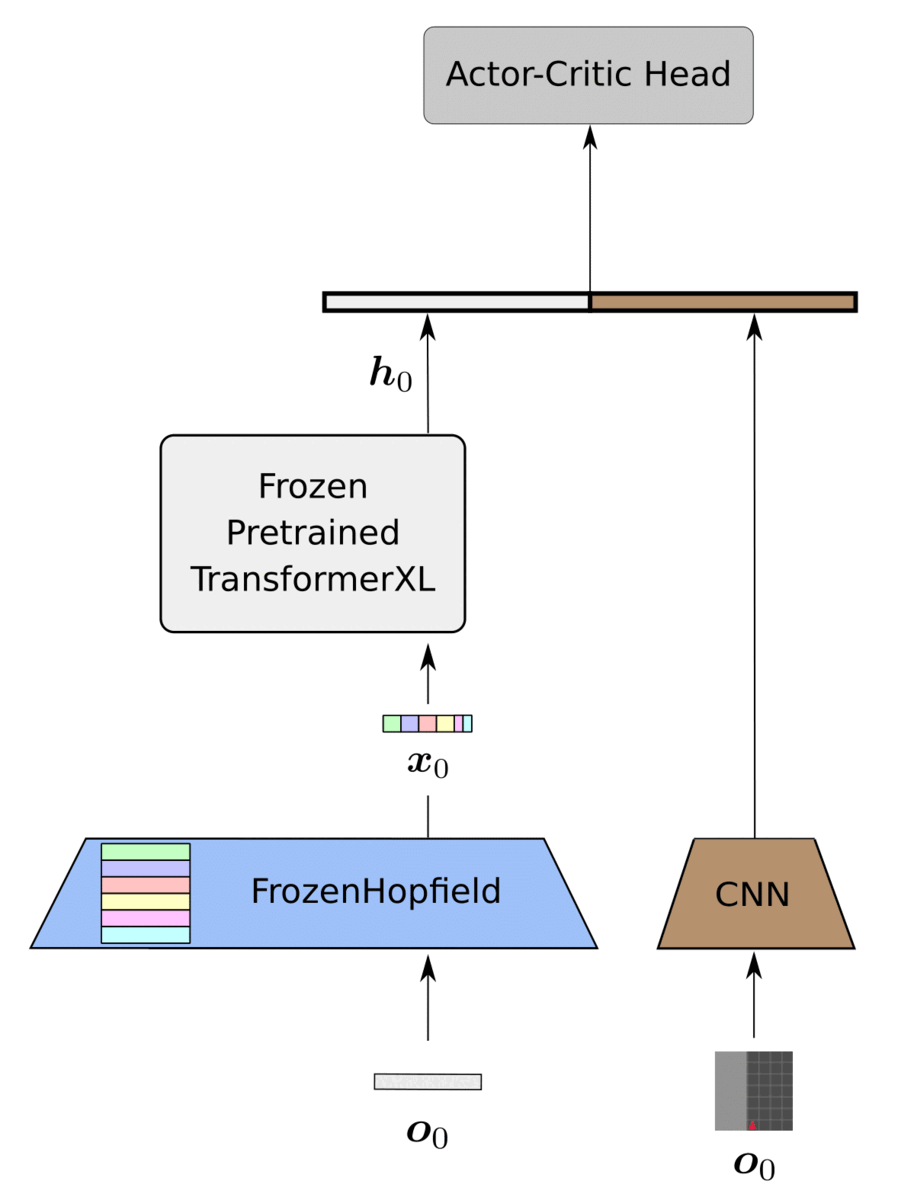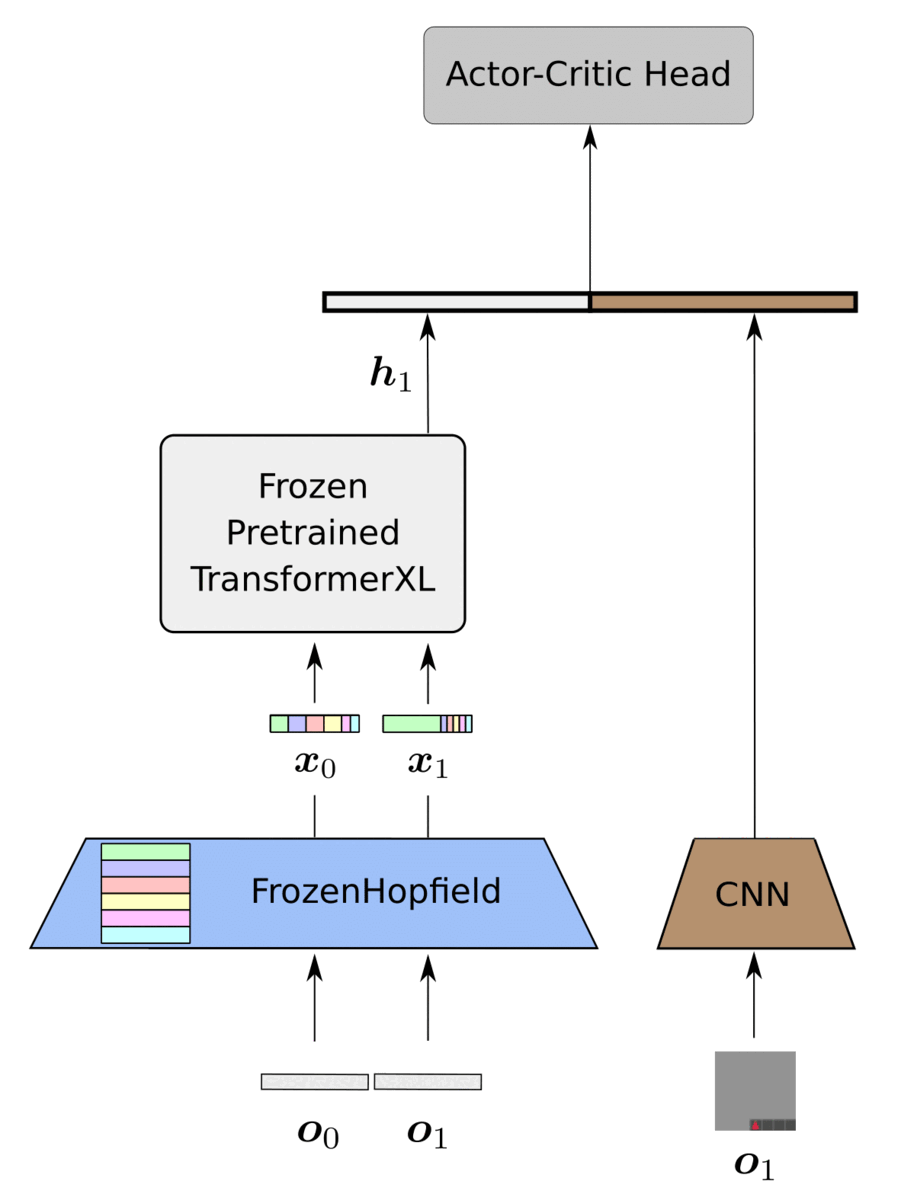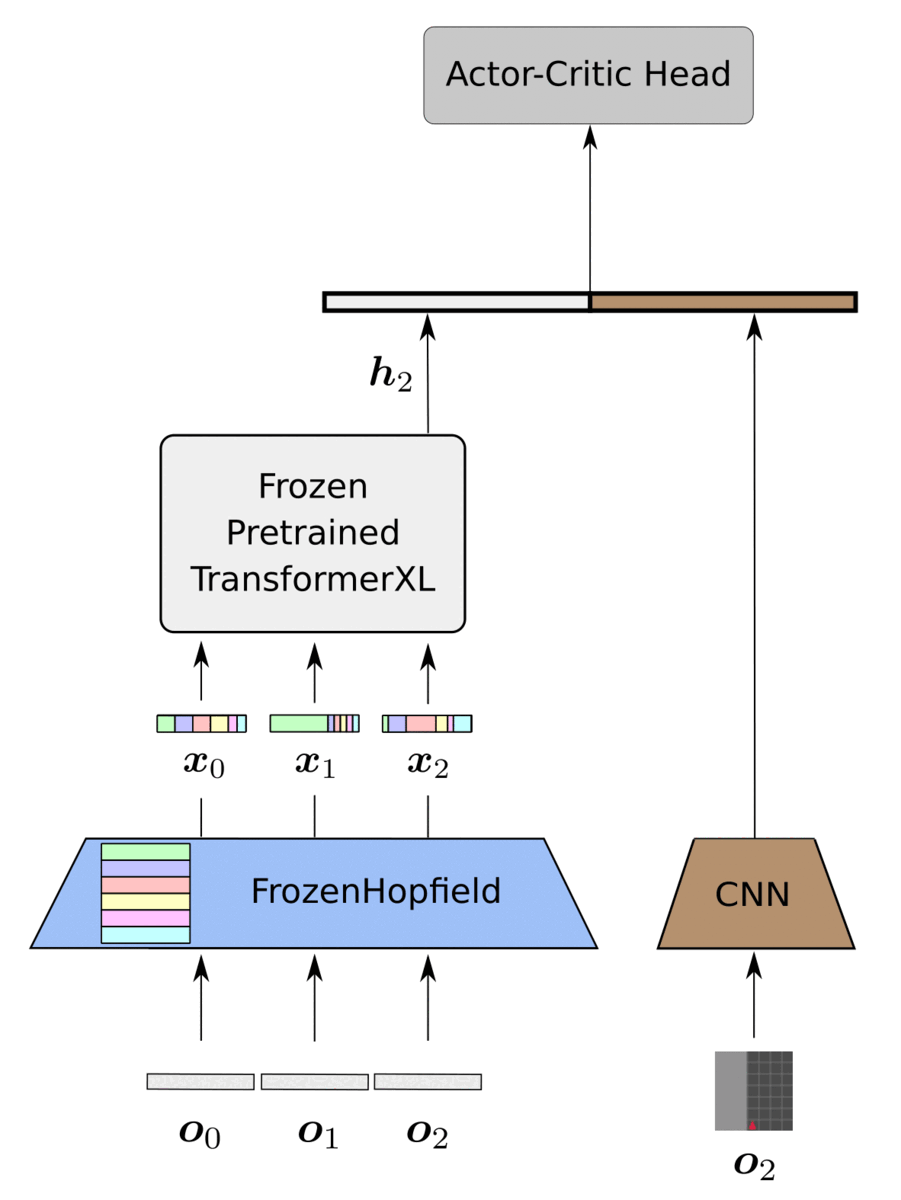
-
CLOOB: Modern Hopfield Networks with InfoLOOB Outperform CLIP
CLOOB (Contrastive Leave One Out Boost) is a novel self-supervised learning method, where modern Hopfield networks boost contrastive learning using upper bounds on the mutual information like InfoLOOB. CLOOB consistently outperforms CLIP at zero-shot transfer learning across different architectures and datasets.
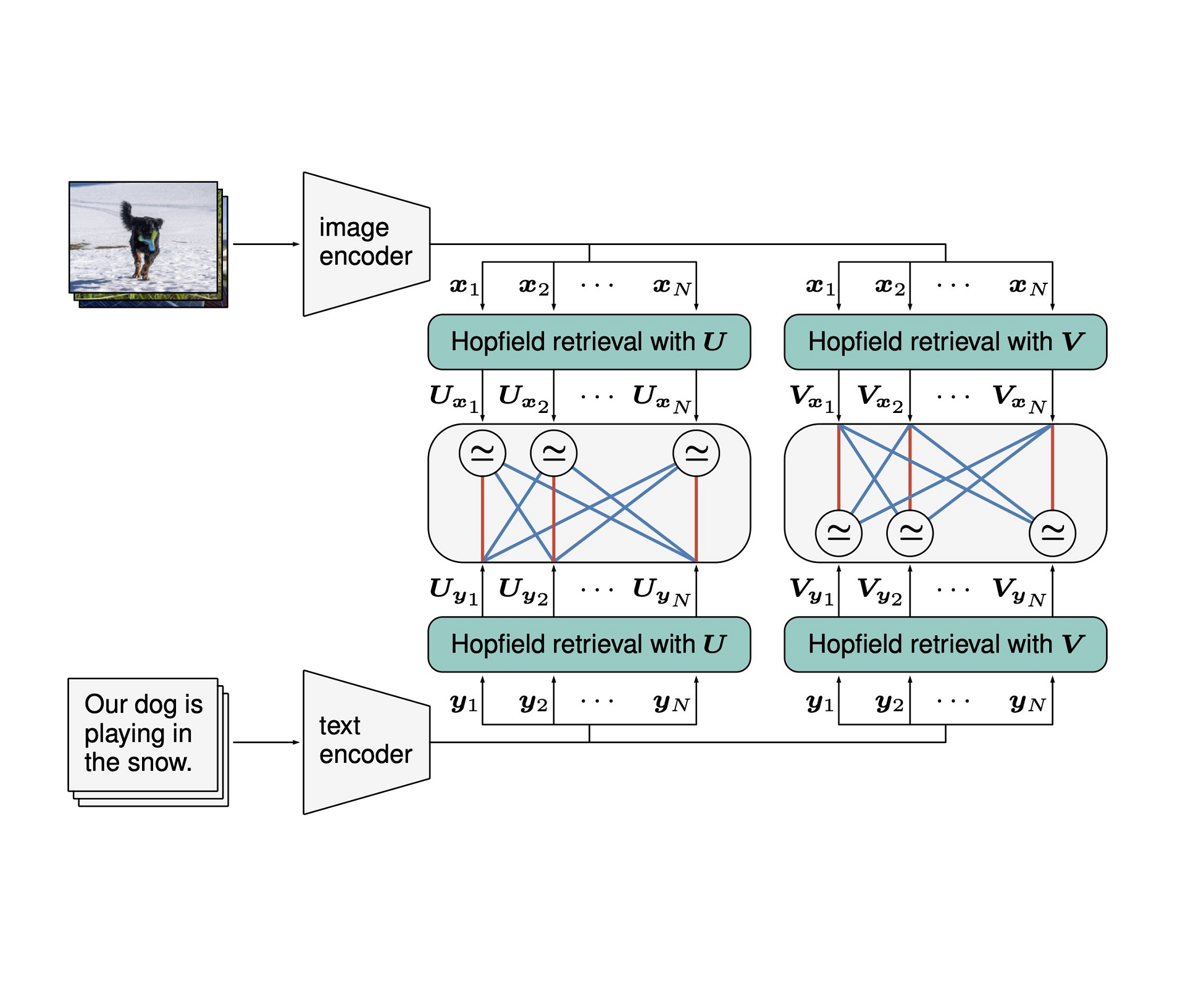
-
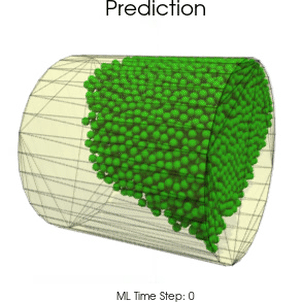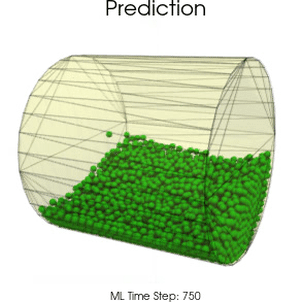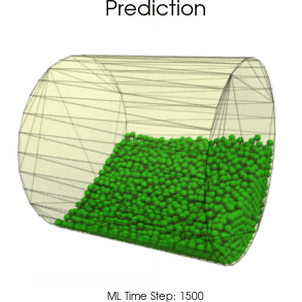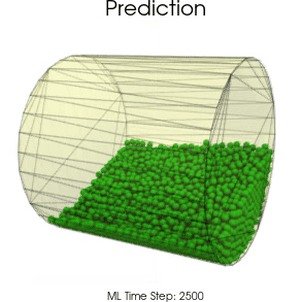
Boundary Graph Neural Networks for 3D Simulations
Boundary Graph Neural Networks (BGNNs) extend traditional GNNs, such that the networks are capable of learning particle - wall interactions by dynamically inserting (virtual particle) nodes, if a particle is near a wall. BGNNs have learned to accurately reproduce 3D granular flows over hundreds of thousands of simulation timesteps, and most notably particles completely stay within the geometric objects without using handcrafted conditions or restrictions.
-
Looking at the Performer from a Hopfield point of view
The recent paper Rethinking Attention with Performers constructs a new efficient attention mechanism in an elegant way. It strongly reduces the computational cost for long sequences, while keeping the intriguing properties of the original attention mechanism. In doing so, Performers have a complexity only linear in the input length, in contrast to the quadratic complexity of standard transformers. This is a major breakthrough in the strive of improving transformer models.

-
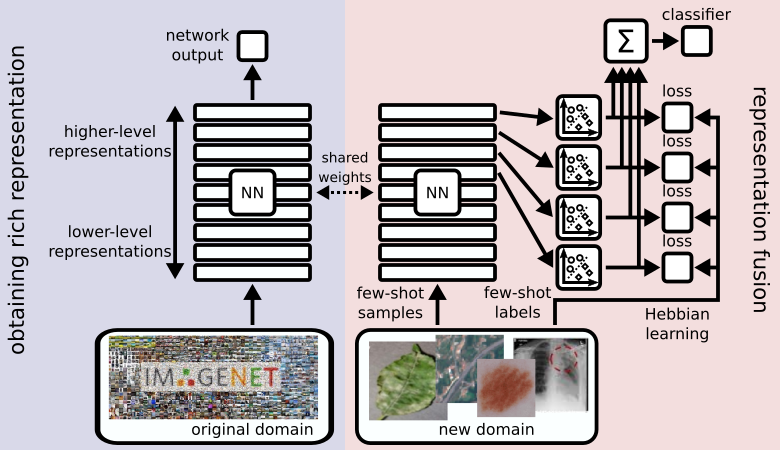
CHEF: Cross Domain Hebbian Ensemble Few-Shot Learning
Few-shot learning aims at learning from few examples, often by using already acquired knowledge and, therefore, enabling models to quickly adapt to new data. The reason for observing new data is a domain shift, that is, a change of the input-target distribution. While most few-shot learning methods can cope with a small domain shift, larger changes in the data distribution, however, are still challenging. CHEF (Cross-domain Hebbian Ensemble Few-shot learning) is a few-shot learning method, that is specifically designed to overcome the problems arising from domain shifts.
-
Align-RUDDER: Learning from Few Demonstrations by Reward Redistribution
We present Align-RUDDER an algorithm which learns from as few as two demonstrations. It does this by aligning demonstrations and speeds up learning by reducing the delay in reward.

-
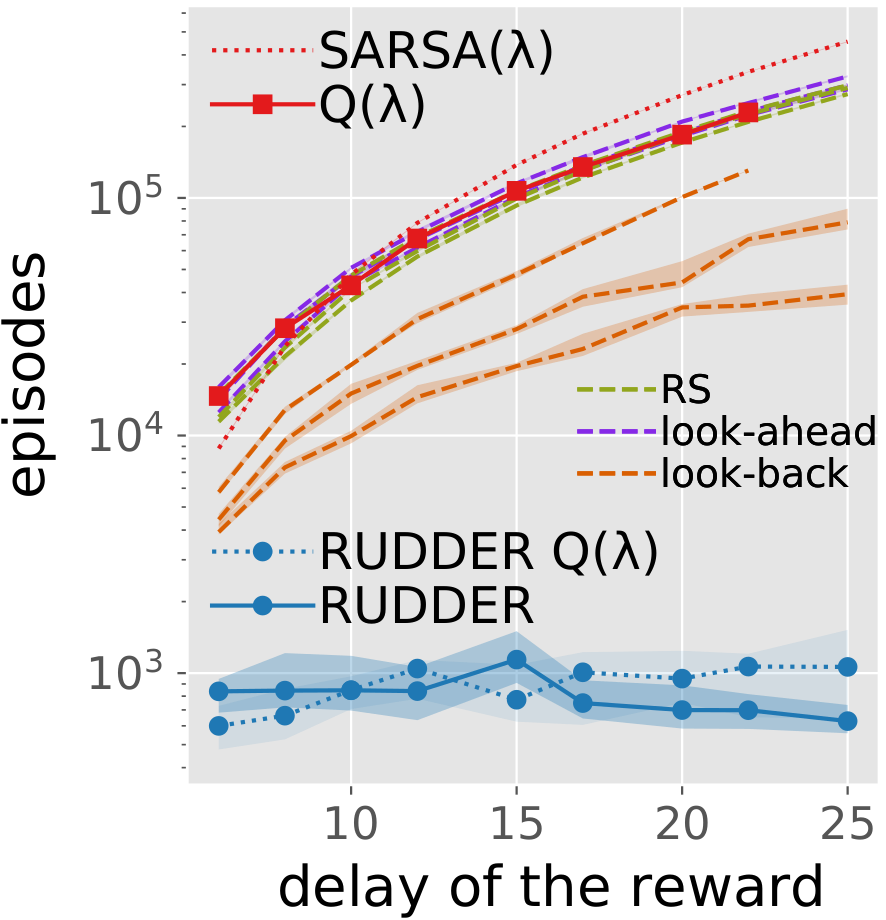
RUDDER - Reinforcement Learning with Delayed Rewards
We introduce a novel model-free RL approach to overcome delayed reward problems. RUDDER directly and efficiently assigns credit to reward-causing state-action pairs and thereby speeds up learning in model-free reinforcement learning with delayed rewards dramatically.
-
Hopfield Networks is All You Need
We introduce a new energy function and a corresponding new update rule which is guaranteed to converge to a local minimum of the energy function. Surprisingly, the new update rule is the attention mechanism of transformer networks introduced in Attention Is All You Need. We use these new insights to analyze transformer/attention models in the paper.
