UPDATE: Align-RUDDER: Learning from Few Demonstrations by Reward Redistribution has been accepted for a long presentation at Internatioal Conference on Machine Learning (ICML), 2022.
This blog post explains the paper Align-RUDDER: Learning from Few Demonstrations by Reward Redistribution. Align-RUDDER is RUDDER with two modifications:
- Align-RUDDER assumes that episodes with high rewards are given as demonstrations.
- Align-RUDDER replaces the RUDDER’s LSTM model by a profile model that is obtained from multiple sequence alignment of demonstrations.
Blog post to RUDDER: Return Decomposition for Delayed Rewards
Only Demonstrations Allow to Solve Complex Tasks in Reinforcement Learning
Reinforcement learning (RL) can solve simple tasks efficiently. However, if tasks become more complex, e.g. consisting of hierarchical sub-tasks, RL requires a huge amount of samples. The reason is that for more complex tasks, episodes with high rewards are difficult to find by current exploration strategies. In contrast, humans and animals learn more efficiently by obtaining high reward episodes through teachers, role models, or prototypes. We believe that in RL this approach can be followed by learning from demonstrations. In this context, we assume that episodes with high rewards are given as demonstrations and we are able to efficiently learn from as few as two episodes.
DeepMind’s well known AlphaGO also uses demonstrations for behavioral cloning (supervised learning of policy networks) and was able to win against the grandmaster Lee Sedol.
More recently, DeepMind’s AlphaStar StarCraft II agent was initialized by behavioral cloning (AlphaStar Supervised), i.e. trained with a large number of demonstrations (human games) and managed similar success stories against professional human players.
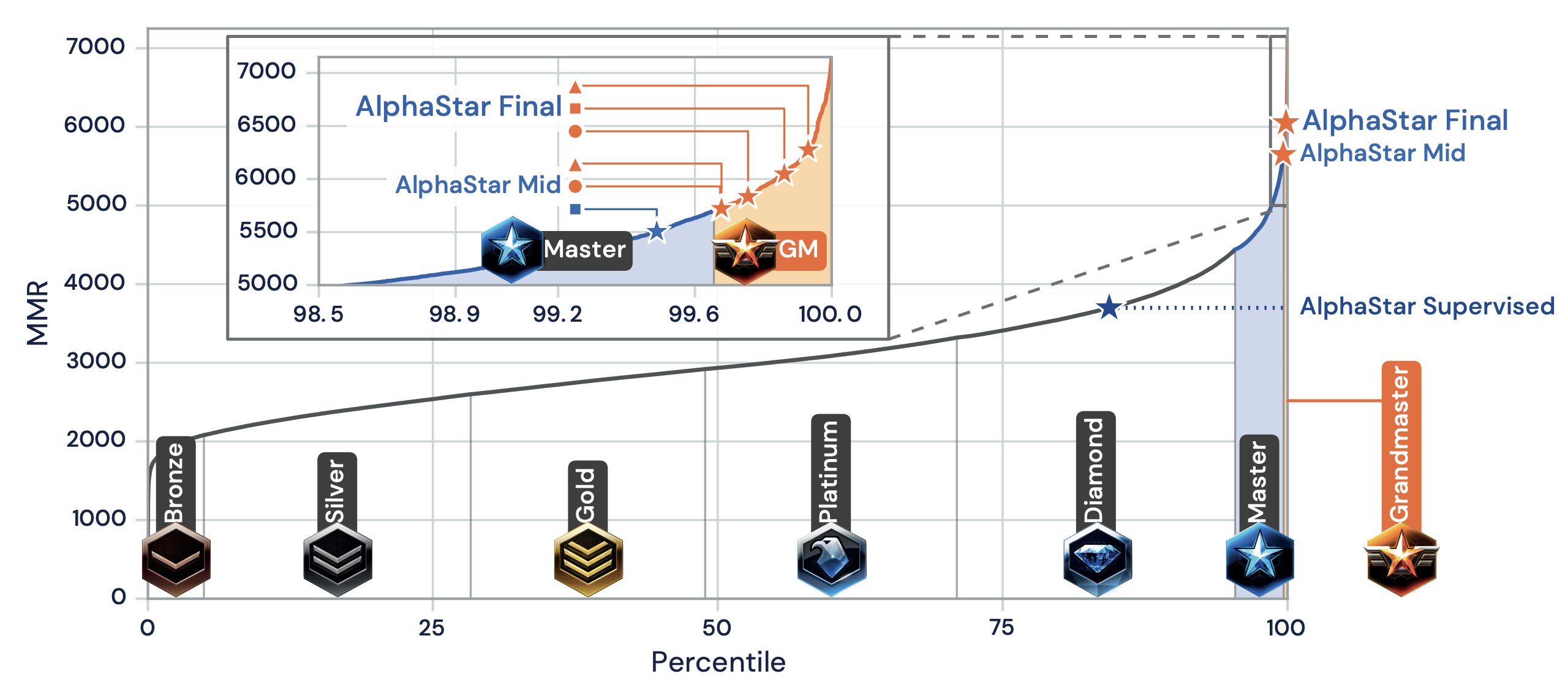 Therefore, we believe that demonstrations are essential when bringing RL to the real world where the relevant tasks are typically highly complex.
Therefore, we believe that demonstrations are essential when bringing RL to the real world where the relevant tasks are typically highly complex.
Delayed Rewards Increase the Complexity of Tasks
Delayed rewards are often episodic or sparse and common in real-world problems. For real-world problems, reward for single actions is often not available, however, episodic rewards are easy as it can be given for achieving a goal or for completing a task. Examples of episodic rewards are board games like chess or Go. Delayed rewards require a long-term credit assignment, which is still a great challenge in reinforcement learning. RUDDER excels in long-term credit assignment for delayed rewards applying the concepts of reward redistribution and return decomposition (for more information see RUDDER blog).
RUDDER Deals with Delayed Rewards Using Reward Redistribution
The main idea of RUDDER is to exploit the fact that the value function is a step function. Complex tasks are hierarchical and are composed of sub-tasks or sub-goals. Completing sub-tasks is reflected by a step in the value function. In this sense, steps indicate events like achievements, failures, and/or changes of environment/information. In general, a step in the value function is a change in return expectation (higher/lower amount of return or higher/lower probability to receive return). The reward can then be redistributed to these steps. In particular, identifying large steps is important since they speed up learning tremendously and results in:
- Large increase of return (after adjusting the policy).
- Sampling more relevant episodes.
Assume we have episodes with high rewards and average rewards. Supervised learning identifies state-action pairs that are indicative for such high rewards. We therefore want to adjust the policy in a way that these state-action pairs are reached more often. The reward redistribution implemented by RUDDER achieves these state-action pair adjustments by using an LSTM to predict the final return at every timestep. Since the hidden state of the LSTM is able to store the history of events, we can focus on key events by computing the difference of predictions, which ultimately establish the contributions to the final return.
To estimate the final return the LSTM uses return decomposition, which relies on pattern recognition. On the left side of the figure shown below, we illustrate a simple environment where an agent needs to collect a key to unlock a door and receive the treasure.
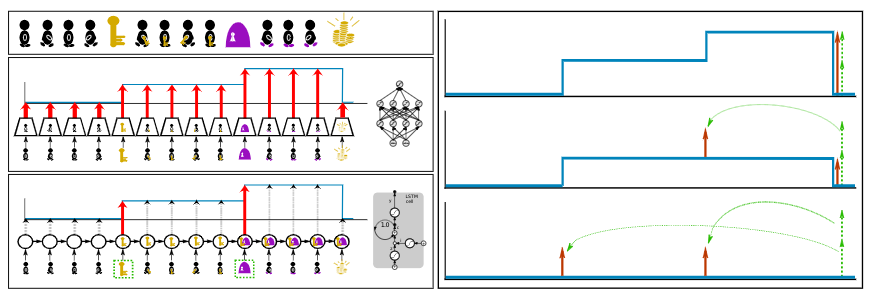
Such a step-function pattern could be detected by a feed-forward neural network (FNN) as shown in the middle section on the left side. The issue is that with a FNN the context information of having a key must be re-extracted in every state and training becomes much more difficult. In contrast, RUDDER uses an LSTM, which is able to store the information of having a key in its hidden state, such that it needs to extract this information only once in the state where the distinct event occurred. Afterwards this context information is only updated when the lock is opened as shown on the bottom left side.
In the right section in the figure above we illustrate how the reward is redistributed according to the step-function. An inherent property of RUDDER is, that by identifying key events and redistributing the reward to them it also pushes the expected future reward towards zero. This considerably reduces the variance of the remaining return and, hence the estimations become more efficient. Zeroing the expected future reward and redistributing the reward is mathematically endorsed by introducing the concepts of return-equivalent decision processes, reward redistribution, return decomposition and optimal reward redistribution. One important contribution established by RUDDER was the introduction of the theoretically founded sequence-Markov decision processes (SDPs), which extend beyond the scope of Markov decision processes (MDPs). The definition of SDPs was thoroughly explained in the appendix of the RUDDER paper including proofs that show that the optimal policy remains unchanged.
For more about reward redistribution theory and its realization in RUDDER using LSTMs, see RUDDER blog.
Align-RUDDER: RUDDER with Few Demonstrations and Multiple Sequence Alignment
Above in our setting, we have assumed complex tasks, where episodes with high rewards are given as demonstrations. To generate such demonstrations is often a tedious task for humans, and a time-consuming process for automated exploration strategies. Therefore, typically only a few demonstrations are available, on which RUDDER’s LSTM model as a deep learning method does not learn well. We have to find an alternative to RUDDER’s LSTM model for reward redistribution. Therefore, we replace RUDDER’s LSTM model by a profile model that is obtained from multiple sequence alignment (MSA) of demonstrations. Profile models can be constructed from as few as two demonstrations as known from bioinformatics and allow for reward redistribution.
So now it’s time for Align-RUDDER, which is RUDDER with two major modifications:
- RUDDER’s lessons replay buffer is replaced by (few) demonstrations
- RUDDER’s LSTM model is replaced by a profile model obtained from MSA of demonstrations
Of course, Align-RUDDER also works with many demonstrations. Align-RUDDER inherits the concept of reward redistribution, which considerably reduces the delay of rewards, thus speeding up or enabling learning.
Reward Redistribution by Align-RUDDER via Multiple Sequence Alignment
In bioinformatics, sequence alignment identifies similarities between biological sequences of different species to determine their evolutionary relationship and conserved regions in different sequences. The underlying problem of this setting is much the same as identifying similarities between demonstrations from different players to determine their underlying strategy. As you can see, these two settings align nicely:
Sequences from different species sharing amino-acids•••• which conserve the biological functionEpisodes• from different players sharing relevant events which conserve the underlying strategy
The following figure shows, on the left, a multiple sequence alignment of biological sequences (triosephosphate isomerase) giving a conservation score. The right panel shows a multiple sequence alignment of demonstrations by different players (here, events have been encoded as amino acids to allow the use of the same tool for alignment).

The alignment techniques in Align-RUDDER identify shared events that represent the underlying strategy. Reward is then redistributed to these shared events (for events see below). The more players share the same event the more reward is redistributed to this event. If an event is shared among all players this indicates achieving a sub-goal or completing a sub-task. The episodes from different players are what we call demonstrations.
Consider one of the toy tasks from the paper. In this task, the environment is a simple grid world with four rooms. The agent starts in the center of the bottom left room and has to reach the goal in the bottom right room. At every location, the agent can move up, down, left and right (if there is no wall in the way). In the first room there is a portal at a random position that teleports the agent into the second room. The portal is introduced to avoid that BC initialization alone solves the task. It enforces that going to the portal entry cells is learned, when they are at positions not observed in demonstrations. From the second room onwards the agent has to traverse the remaining rooms by going through the doors connecting them. Reward is only given at the end of the episode. The figure below shows an exemplary demonstration where the agent has reached the goal.
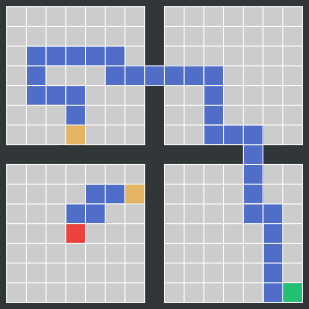
The reward redistribution of Align-RUDDER consists of the following five steps:
-
Define events: An alignment is only reliable if many equal (or similar) symbols are aligned. If there are many different symbols, the chance that two sequences share the same symbols are small and aligning them gives an almost random result. Therefore, episodes should be described as sequences of events, where the number of events is small. These events can be the original state-action pairs or clusters thereof. A sequence of events is obtained from a state-action sequence by substituting states or state-actions by their cluster identifier. In order to cluster state-actions, a similarity among or distance between them has to be computed. Consequently, we need a distance- or similarity matrix of the state-actions, or a vector-representation of them. A similarity matrix can for example be built via successor representation.
In order to cluster states, a similarity measure between them is required. We suggest to use the “successor representation” Dayan, 1993 of the states, which gives a similarity matrix based on how connected two states are given a policy. For computing the successor representation, we use the demonstrations combined with state-action sequences generated by a random policy. For high dimensional state spaces “successor features” Barreto et al., 2017 can be used.
Possible clustering algorithms are amongst others affinity propagation (similarity-based) [Frey and Dueck] or hierarchical clustering (distance-based).
The figure below shows an examplified clustering for demonstration purpose. Each color represents a cluster. The starting point (
 ), the goal (
), the goal ( ), the traversing of each of the four rooms (
), the traversing of each of the four rooms ( ,
,  ,
,  ,
,  ) and their respective doors/teleporters (
) and their respective doors/teleporters ( ,
,  ,
,  ) are clusters. These are the important clusters indicating achieving sub-goals via completing sub-tasks.
) are clusters. These are the important clusters indicating achieving sub-goals via completing sub-tasks.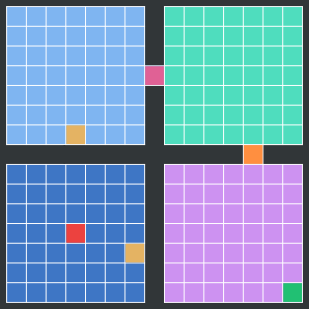
The figure below shows three demonstrations after clustering and assigning each event to their respective cluster identifier.

-
Determine an alignment scoring scheme: The alignment algorithm requires a scoring system to distinguish similar events from dissimilar events. A scoring matrix \(\unicode{x1D54A}\) has entries \(\unicode{x1D564}_{i,j}\) that give the score for aligning event \(i\) with \(j\).
The MSA score \(S_{\mathrm{MSA}}\) of a multiple sequence alignment is the sum of all pairwise scores:
\[S_{\mathrm{MSA}} = \sum_{i,j,i<j} \sum_{t=0}^L \unicode{x1D564}_{x_{i,t},x_{j,t}} \ ,\]where \(x_{i,t}\) and \(x_{j,t}\) are events at position \(t\) in the alignment for the sequences \(\tau_i\) and \(\tau_j\), respectively. \(L\) is the alignment length.
In the alignment, events should have the same probability of being aligned as they would have if we knew the strategy and aligned demonstrations accordingly. The theory of high scoring segments allows us to derive such a scoring scheme.
A priori, we only know that a relevant event should be aligned to itself, while we do not know which events are relevant. Furthermore, events occuring with low probability receive a higher score when being aligned to themselves (a match with very low probability to be observed randomly). Prior knowledge can also be incorporated in the construction of the scoring matrix. Such prior knowledge could be that two events are interchangeable, and therefore the corresponding entry for a match between them in the scoring matrix would be high allowing the MSA algorithm to align these events.
An alignment algorithm maximizes the MSA score \(S_{\mathrm{MSA}}\) and, thereby, aligns events \(i\) and \(j\) with probability \(q_{ij}\).
High values of \(q_{ij}\) means that the algorithm often aligns events \(i\) and \(j\) using the scoring matrix \(\unicode{x1D54A}\) with entries \(\unicode{x1D564}_{i,j}\).
According to Theorem 2 and Equation [3] in this paper, asymptotically with the sequence length, we have
\(\unicode{x1D564}_{i,j} = \frac{\ln(\frac{q_{ij}}{(p_i \ p_j)})}{\lambda^*}\)
where \(\lambda^*\) is the single unique positive root of \(\sum_{i=1,j=1}^{n,n} p_i p_j \exp(\lambda \unicode{x1D564}_{i,j}) =1\) (Equation [4] in this paper).
We now can choose a desired probability \(q_{ij}\) and then compute the scoring matrix \(\unicode{x1D54A}\) with entries \(\unicode{x1D564}_{i,j}\). High values of \(q_{ij}\) should indicate relevant events for the strategy.
A priori, we only know that a relevant event should be aligned to itself, while we do now know which events are relevant.
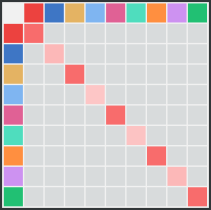
Therefore we set \(q_{ij}\) to large values for every \(i=j\) and to low values for \(i\not=j\). Concretely, we set \(q_{ij}=p_i-\epsilon\) for \(i=j\) and \(q_{ij}=\epsilon/(n-1)\) for \(i\not=j\), where \(n\) is the number of different possible events. Events with smaller \(p_i\) receive a higher score \(\unicode{x1D564}_{i,i}\) when aligned to themselves since this is seldom observed randomly.The following figure shows a scoring matrix for our toy task, without including any prior knowledge. We get high scores on the diagonal (i.e. aligning only the same events) and low scores everywhere else. Furthermore, rare events, such as going through the doors or teleporters, get higher values making it more likely that they are aligned.
-
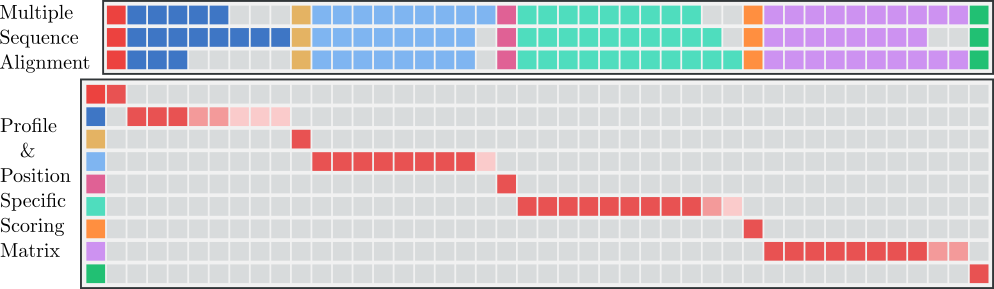
Perform MSA: MSA first produces pairwise alignments between all demonstrations. Afterwards, a guiding tree is produced via hierarchical clustering, which clusters the sequences according to their pairwise alignment scores. Demonstrations which follow the same strategy appear in the same cluster in the guiding tree. Each cluster is aligned separately via MSA to address different strategies. In our example we use ClustalW but other MSA methods can be used as well.
There are two important parameters to MSA we didn’t discuss until now but only hinted at, namely gap-open and gap-extention pentalties. We set these to zero so only the scoring matrix \(\unicode{x1D54A}\) determines the alignment.
-
Compute the profile model and the PSSM: From the alignment we get the following: (a) an MSA profile matrix with column-wise event frequencies and (b) a position-specific scoring matrix (PSSM) which is used for aligning new sequences to the profile.
The figure below shows how our three demonstrations are aligned with the above scoring matrix. You can see, that only the same events are aligned, otherwise a gap is inserted. In this example the “door” or “teleport arrival” events align nicely which is what we would expect. From this alignment it can easily be seen that there are four sub-tasks to solve (an event shared by all aligned demonstrations and having low probability), i.e. traversing each room and entering the respective door or teleporter (which corresponds to reaching the goal in the last room).
-
Redistribute the reward: Our reward redistribution is based on the profile model. A sequence \(\tau=e_{0:T}\) (\(e_t\) is an event at position \(t\)) can be aligned to the profile, giving the score \(S(\tau) = \sum_{t=0}^L \unicode{x1D564}_{x_t,t}\), where \(\unicode{x1D564}_{i,t}\) is the alignment score for event \(i\) at position \(t\), \(x_t\) is the event at position \(t\) of sequence \(\tau\) in the alignment, and \(L\) is the profile length. Note that \(L \geq T\) and \(x_t \not= e_t\), since gaps are present in the alignment. The redistributed reward is proportional to the difference of scores of two consecutive events based on the PSSM, i.e. the reward for \(R_{t+1}\) is redistributed according to the following equation (where \(C\) is just a normalization constant):
\[R_{t+1} = \left( S(\tau_t) - S(\tau_{t-1}) \right) \ C\]If \(\tau_t=e_{0:t}\) is the prefix sequence of \(\tau\) of length \(t+1\), then the reward redistribution is
\(R_{t+1} = \left( S(\tau_t) - S(\tau_{t-1}) \right) \ C \ = \ g((s,a)_{0:t}) - g((s,a)_{0:t-1})\),
\(R_{T+2} \ = \ \tilde{G}_0 \ - \ \sum_{t=0}^T R_{t+1}\),
\(C = \frac{E_{\mathrm{demo}} \left[\tilde{G}_0 \right]}{E_{\mathrm{demo}} \left[ \sum_{t=0}^T S(\tau_t) \ - \ S(\tau_{t-1}) \right] }\)
where \(\tilde{G}_0=\sum_{t=0}^T\tilde{R}_{t+1}\) is the original return of the sequence \(\tau\) and \(S(\tau_{-1})=0\). \(E_{\mathrm{demo}}\) is the expectation over demonstrations, and \(C\) scales \(R_{t+1}\) to the range of \(\tilde{G}_0\). \(R_{T+2}\) is the correction reward (see RUDDER paper), with zero expectation for demonstrations:
\(E_{\mathrm{demo}} \left[ R_{T+2}\right] = 0\).
Since \(\tau_t=e_{0:t}\) and \(e_t=f(s_t,a_t)\), we can set \(g((s,a)_{0:t})=S(\tau_t) C\).
We ensured strict return equivalence, since \(G_0=\sum_{t=0}^{T+1} R_{t+1} = \tilde{G}_0\).
The redistributed reward depends only on the past, that is, \(R_{t+1}=h((s,a)_{0:t})\).
For computational efficiency, the profile alignment of \(\tau_{t-1}\) can be extended to a profile alignment for \(\tau_t\) like exact matches are extended to high-scoring sequence pairs with the BLAST algorithm.A new sequence is aligned to the profile, then the score for each event is calculated as the sum of scores up to, and including, this event (as seen in the figure below). The redistributed reward is then the difference of scores of two consecutive sub-sequences \(\tau_{t-1}\) and \(\tau_{t}\) aligned to the profile.

The figure below shows the final reward redistribution.

Comparison on a Grid World of Align-RUDDER and Competitors for Learning on Few Demonstrations
Align-RUDDER is compared to Behavioral Cloning with \(Q\)-learning (BC+\(Q\)) and Deep \(Q\)-learning from Demonstrations (DQfD). GAIL, which has been designed for control in continuous observation spaces, failed to solve the two artificial tasks, as reported previously for similar tasks in SQIL. In addition to the above setting with four rooms we also performed experiments with eight rooms. Other than the number of rooms both tasks are the same. An episode ends after 200 time steps or when the agent reaches the goal. To enforce that the agent reaches the goal with the fewest steps possible, we reduce the final reward for every time step the agent needed to get to the goal.
The plots below shows the number of episodes to achieve 80% of the average reward of the demonstrations vs. the number of demonstrations averaged over 100 trials.
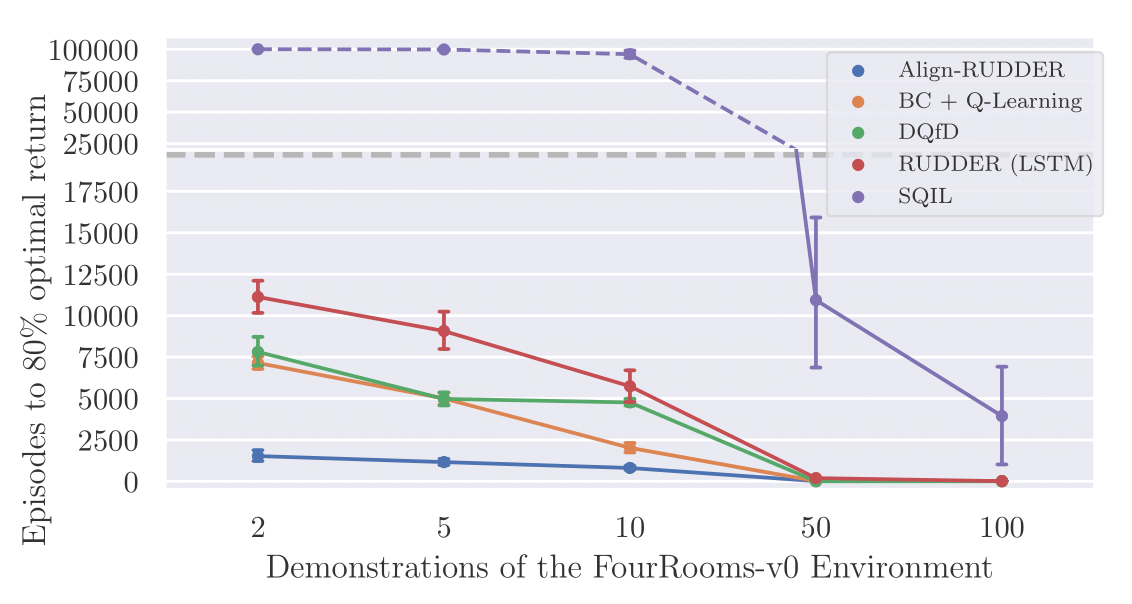
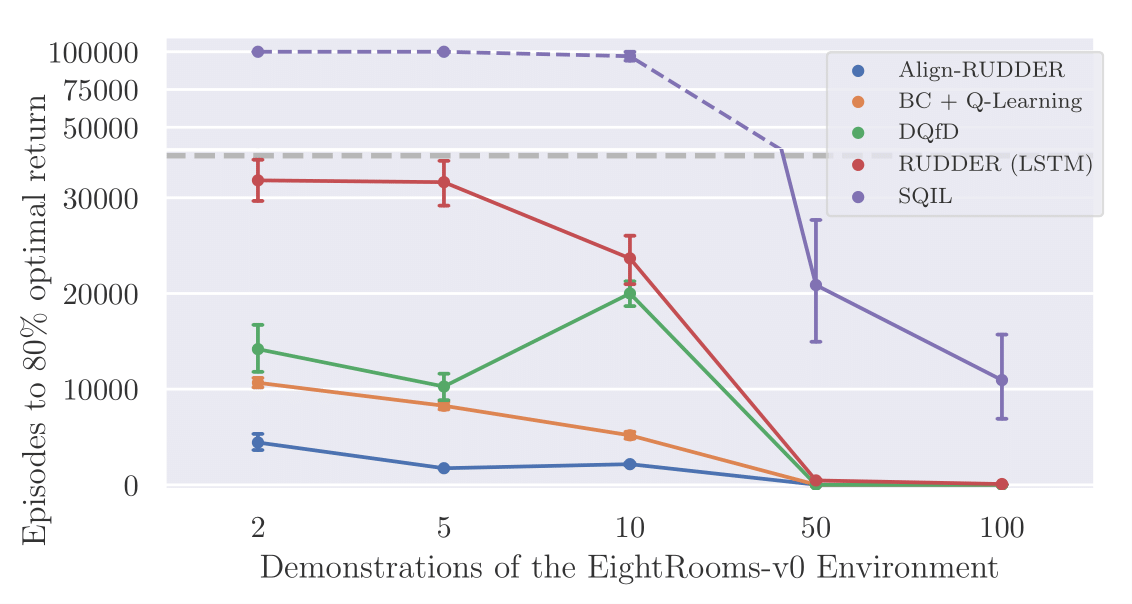
Align-RUDDER significantly outperforms all other methods, in particular with few demonstrations.
Align-RUDDER Evaluated on Minecraft
We tested Align-RUDDER on the very challenging MineRL NeurIPS Competition task (ObtainDiamond) where a reinforcement learning agent has to navigate through the complex 3D, first-person, Minecraft environment to collect a diamond. Episodes end due to the agent dying, successfully obtaining a diamond, or reaching the maximum step count of 18,000 frames (15 minutes). An agent needs to solve several sub-tasks to reach its goal. The observation space of an agent consists of visual input and player inventory and attributes. The action space consists of the Cartesian product of continuous view adjustment (turning and pitching), binary movement commands (left/right, forward/backward), and discrete actions for placing blocks, crafting items, smelting items, and mining/hitting enemies. The primary goal of the competition is to foster the development of algorithms which can efficiently leverage human demonstrations to drastically reduce the number of samples needed to solve complex, hierarchical, and sparse environments [Guss et al.]. Participants need to obtain a diamond within 8,000,000 samples in less than four days using hardware no more powerful than a NG6v2 instance (AIcrowd MineRL Competition). This challenge was first introduced in 2019 and none of the participants was able to collect a diamond (BBC News report). Since Reinforcement learning algorithms struggle with learning tasks that have sparse and delayed rewards, participants struggled to find a solution although they relied on state-of-the-art methods, i.e. Deep Q-learning from Demonstrations (DQfD) [Hester et al.].
We didn’t use the intermediate rewards given by achieving sub-goals from the challenge, since our method is supposed to discover such sub-goals via redistributing reward to them. We only give reward for collecting the diamond.
Following are the five steps of Align-RUDDER applied to Minecraft:
 Step (I): Define events and map demonstrations into sequences of events. First, we extract the sequence of states from human demonstrations, transform images into
feature vectors using a pre-trained network and transform them into a sequence of consecutive state deltas (concatenating image feature vectors and inventory states). We cluster the resulting state deltas and remove clusters with a large number of members and merge smaller clusters. In the case of demonstrations for the ObtainDiamond task in Minecraft the resulting clusters correspond to obtaining specific resources and items required to solve the task.
Then we map the demonstrations to sequences of events.
Step (I): Define events and map demonstrations into sequences of events. First, we extract the sequence of states from human demonstrations, transform images into
feature vectors using a pre-trained network and transform them into a sequence of consecutive state deltas (concatenating image feature vectors and inventory states). We cluster the resulting state deltas and remove clusters with a large number of members and merge smaller clusters. In the case of demonstrations for the ObtainDiamond task in Minecraft the resulting clusters correspond to obtaining specific resources and items required to solve the task.
Then we map the demonstrations to sequences of events.
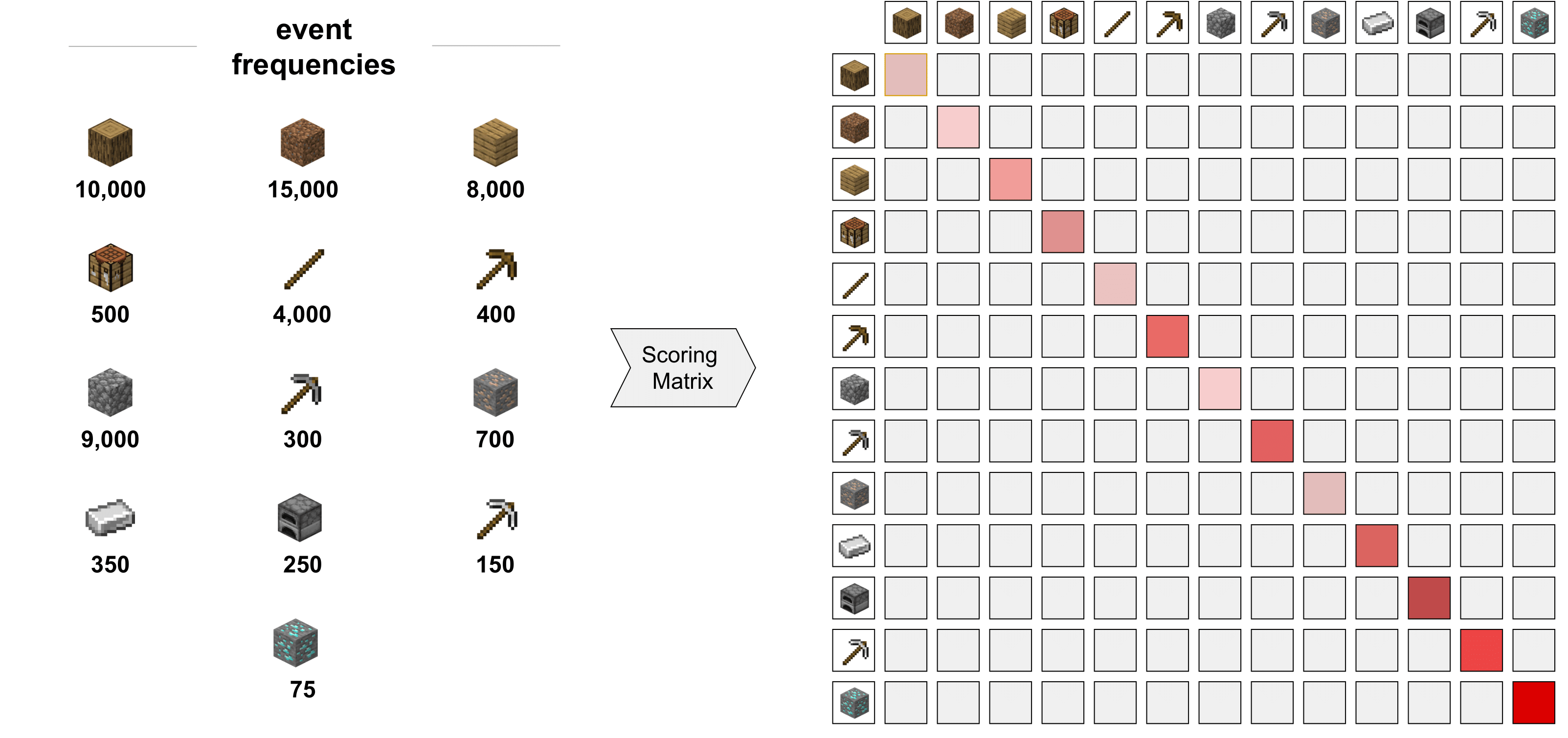 Step (II): Construct a scoring matrix using event probabilities from demonstrations for diagonal elements and setting off-diagonal to a constant value. The scores in the diagonal position are proportional to the inverse of the event frequencies. Thus, aligning rare events has higher score. Darker colors signify higher score values.
Step (II): Construct a scoring matrix using event probabilities from demonstrations for diagonal elements and setting off-diagonal to a constant value. The scores in the diagonal position are proportional to the inverse of the event frequencies. Thus, aligning rare events has higher score. Darker colors signify higher score values.
 Step (III): Perform multiple sequence alignment (MSA) of the demonstrations. The MSA algorithm maximizes the pairwise sum of scores of all alignments. The score of an alignment at each position is given by the scoring matrix. As the off-diagonal entries are negative, the algorithm will always try to align an event to itself, while giving preference to events which give higher scores.
Step (III): Perform multiple sequence alignment (MSA) of the demonstrations. The MSA algorithm maximizes the pairwise sum of scores of all alignments. The score of an alignment at each position is given by the scoring matrix. As the off-diagonal entries are negative, the algorithm will always try to align an event to itself, while giving preference to events which give higher scores.
 Step (IV): Compute a position-specific scoring matrix (PSSM). This matrix can be computed using the MSA (Step (III)) and the scoring matrix (Step (II)). Every column entry is for a position from the MSA. The score at a position (column) and for an event (row) depends on the frequency of that event at that position in the MSA. For example, the event in the last position is present in all the sequences, and thus gets a high score at the last position. But it is absent in the remaining position, and thus gets a score of zero elsewhere.
Step (IV): Compute a position-specific scoring matrix (PSSM). This matrix can be computed using the MSA (Step (III)) and the scoring matrix (Step (II)). Every column entry is for a position from the MSA. The score at a position (column) and for an event (row) depends on the frequency of that event at that position in the MSA. For example, the event in the last position is present in all the sequences, and thus gets a high score at the last position. But it is absent in the remaining position, and thus gets a score of zero elsewhere.
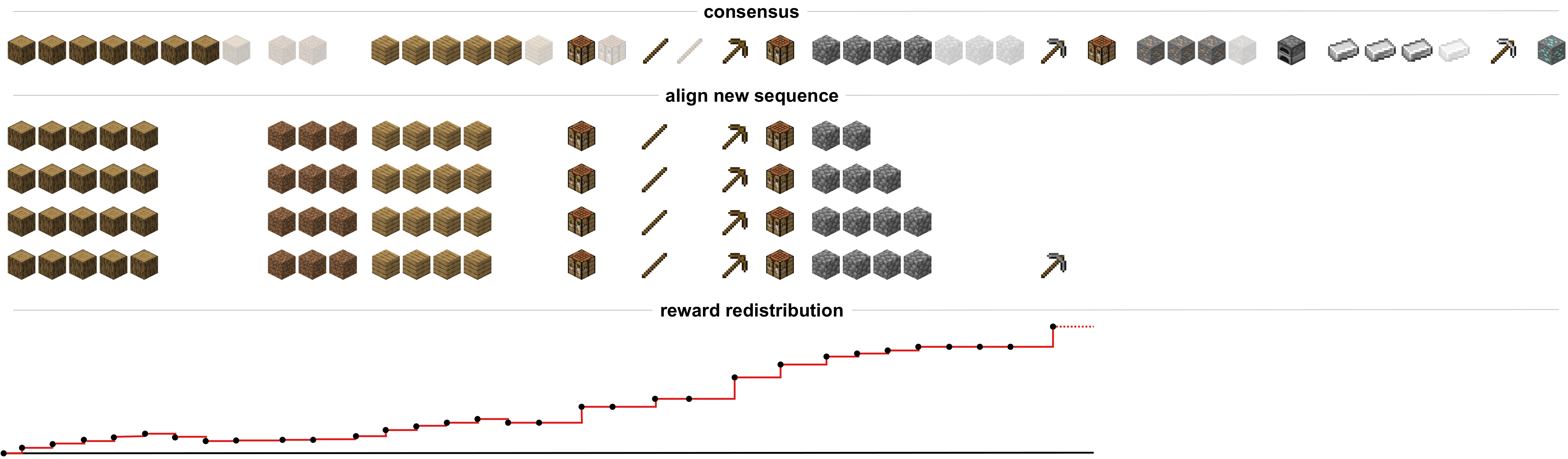 Step (V): A new sequence is aligned step by step to the profile model using the PSSM, resulting in an alignment score for each sub-sequence. The redistributed reward is then proportional to the difference of scores of subsequent alignments.
Step (V): A new sequence is aligned step by step to the profile model using the PSSM, resulting in an alignment score for each sub-sequence. The redistributed reward is then proportional to the difference of scores of subsequent alignments.
Results on Minecraft: With Align-RUDDER we tackled the ObtainDiamond task and managed to collect a diamond in 0.1% of the time over multiple runs and seeds with similar constrains as proposed by the challenge organizers. To put this in context, if one splits the ObtainDiamond task into 31 sub-tasks and assign a 50% success rate to each task, the resulting success probability to collect a diamond is approximately \(4.66 \times 10^{-10}\). This is an one in two billion chance of success. In comparison, our method performs two million times better.
The 31 sub-tasks include collecting log, crafting planks or smelting iron ingots and were extracted from the provided human demonstrations, not hard-coded. The sub-tasks emerged by aligning the players inventory items and are extracted from the resulting profile model. In the case of Minecraft the profile model already determines a sequence of achievable sub-goals and consiquently reward can be redistributed uniformly. For each unique sub-task we then train an agent and select between the corresponding agents according to the profile model. In the following figure we illustrate an overview of a profile model based on human demonstrations using the player inventory. In the following video we summarize the main aspects of tackling the ObtainDiamond task by Align-RUDDER.
Material
Paper: Align-RUDDER: Learning from Few Demonstrations by Reward Redistribution
Github repo: Align-RUDDER
Paper: RUDDER: Return Decomposition for Delayed Rewards
Blog: RUDDER: Return Decomposition for Delayed Rewards
Music: Scott Holmes - Upbeat Party (CC0 license)
Correspondence
This blog post was written by Markus Hofmarcher and Marius-Constantin Dinu.
Contributions by Vihang Patil, José Arjona-Medina, Johannes Brandstetter and Sepp Hochreiter.